By Tim McVinish
Retrieval Augmented Generation (RAG) has emerged as one of the leading ways for business to leverage the power of AI. So what is it? RAG is an AI framework that enhances the capabilities of large language models (LLMs) by combining them with external knowledge sources. Put another way, it’s a system that can enable AI models to securely access and utilise your up-to-date, proprietary information when generating responses. Think of it as giving an AI assistant the ability to quickly “look up” facts in real-time before answering questions. The result of this greatly reduces the chances of the dreaded AI hallucination. It also means that creating intelligent chat bots, fully aware of your business’s unique data is possible, and that can be a huge value unlock!
The need for RAG – challenges with Large Language Models (LLM)
So, you’ve likely tried asking ChatGPT questions relating to your business. How did that go? No doubt you were somewhat disappointed by the answers that it returned. Maybe it mistook an industry specific term for a more general interpretation? Maybe it replied saying that it did not know what you’re talking about? Or, perhaps it replied with something semi-plausible sounding but completely made up and confidently lied to you?
As impressive as LLM’s are, their shortcomings are largely since they’re trained on broad, fixed datasets, often scraped from the open web. As a result, their information can become outdated and does not encompass a business’ internal, specialised knowledge. But… we can overcome that with RAG!
Benefits of RAG for businesses – enhanced accuracy and relevance
By securely giving LLMs access to a business’s real-time, proprietary data, RAG systems provide significantly improved response quality. They become aware of your data, specific terminology, and any other context which you provide them. Setup correctly, a RAG system can provide huge value across a number of roles. A few examples of these could be:
Customer Service:
Chatbots and Virtual Assistants: RAG models can access up-to-date customer data and knowledge bases to provide accurate, contextually relevant responses, leading to better customer satisfaction and efficient query resolution.
Healthcare:
Clinical Decision Support: RAG models can assist healthcare professionals by retrieving the latest medical research, patient records, and treatment protocols, supporting informed decision-making and personalised patient care.
Finance:
Market Analysis and Reporting: Financial analysts can use RAG models to access real-time market data, historical trends, and financial reports, enabling insightful analyses and forecasts.
Legal:
Document Review and Compliance: RAG models can streamline the review of legal documents by retrieving relevant case laws, regulations, and precedents, ensuring thorough and accurate compliance checks.
Onboarding and change management:
Providing employees with A RAG system aware of policies and procedures and manuals can creates a powerful virtual assistant to greatly reduce onboarding and training times.
How RAG works – basic mechanism
To understand how a RAG system works let’s first break it into two parts and have a high-level look.
- the retrieval process, where the system looks through its’ provided knowledge sources for any information relevant to the user’s question. Information returned is referred to as Grounding information as it will be used to “ground” the final response generated by the LLM.
- the generation process, where the user’s question and grounding information are submitted to the LLM along with instructions for the AI to use the grounding information to help it generate its answer to the question.
Put the two parts together and the system operates like an open-book exam. Or, a librarian quickly surfacing related information on a given topic, then submitting their findings to a writer who formulates a response based on the librarian’s provided information.
Keeping these analogies in mind, let’s dig a little deeper. First, before any information can be retrieved, it must be loaded into the system and indexed, ready for the librarian. The indexing process involves passing our data through an embedding model, where the semantic meaning of our data is captured and represented in an array of vectors. The resulting vectors are loosely analogous to a multidimensional matrix, or scatter plot where each dimension represents how strongly something rates for a given trait/value. However, our vectors contain hundreds, or even thousands of dimensions which allow an AI to quickly understand the meaning of our data.
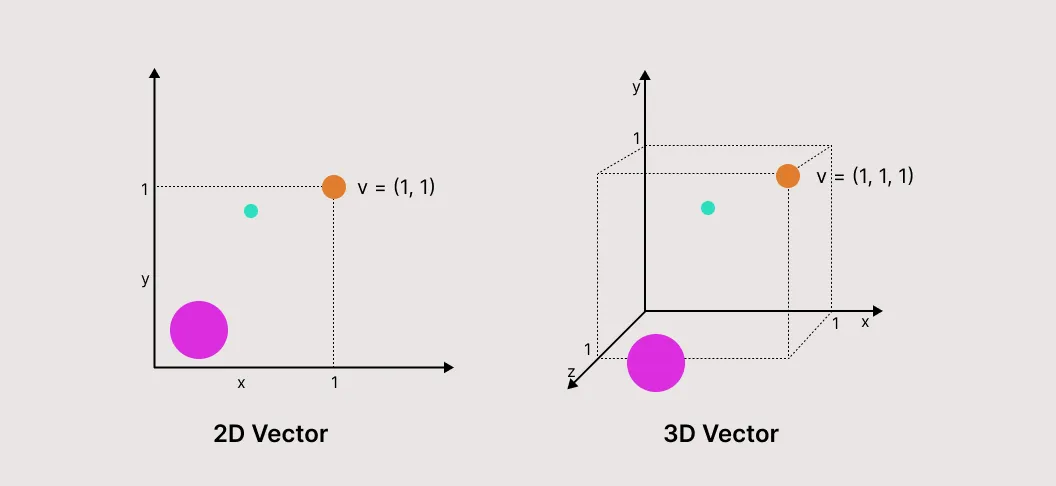
Now, when a user’s question is submitted it runs through the same embedding process. This step is often referred to as query encoding. The resulting vectors are compared against our database to rapidly find the most semantically similar entries and return relevant grounding information. Both the original question and the grounding information are finally submitted to an LLM along with instructions to use the grounding information to help generate a response
Wrapping up
For businesses eager to start leveraging AI, a RAG system can be an effective and achievable first step. By enabling LLMs to access and utilise your proprietary data, RAG systems offer a practical solution to many of the challenges faced when implementing AI in business contexts. RAG enhances accuracy, reduces the risk of AI hallucinations, and provides contextually relevant responses across various industries and functions. Moreover, a RAG system’s ability to adapt to a company’s specific needs and data make it a powerful tool when creating intelligent, business-aware AI assistants.



